Introduction
With the rise of Large Language Models (LLMs) like OpenAI's GPT-4 and Anthropic's Claude, the demand for efficient ways to handle and process the vast amounts of data they utilize has surged. Many might be familiar with the standard relational databases, but the unique requirements of LLMs often require the use of more specialized tools.
Because of this, we've seen a new type of database emerge: Vector databases.
What is a Vector Database?
A vector database is a specific kind of database designed to convert data – usually textual data – into multi-dimensional vectors (also known as vector embeddings) and store them accordingly. These vectors act as mathematical depictions of characteristics or qualities. The number of dimensions in each vector can vary widely, spanning from just a few to several thousands, based on the data's intricacy and detail level.
This allows for efficient and effective analysis and comparison of data points, enabling tasks such as similarity searches and clustering. The use of vectors in a database can greatly enhance data processing capabilities and enable advanced data-driven applications.
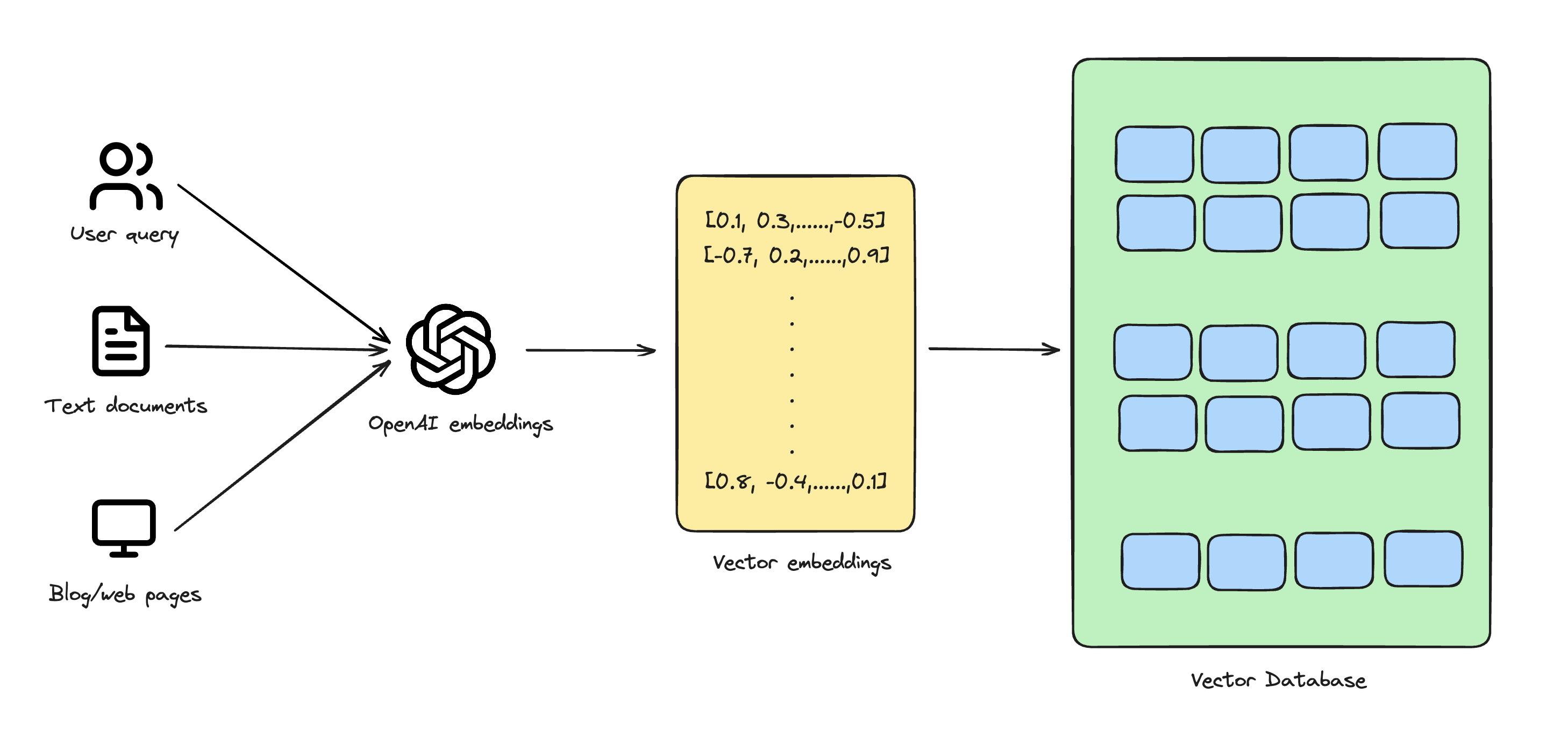
Imagine you're writing a lengthy research paper, and instead of reading each page individually, you have a special folder that turns every page into a unique bar code. These bar codes represent the main points and details of each page. Some bar codes might be simple with just a few lines, while others are incredibly complex with thousands of lines, depending on the depth of the content on that page.
Now, if you want to find pages with similar themes or group them by topics, you just have to compare their bar codes quickly. This method makes managing and understanding your research much easier and more efficient, just like how vector databases handle and analyze data.
Examples of Vector Databases

There are several vector databases available in the market today. Here are some of the most popular ones, based on the usage we've seen in AI apps built on Vercel:

Pinecone
Pinecone makes it easy to provide long-term memory for high-performance AI applications. It’s a managed, cloud-native vector database with a simple API and no infrastructure hassles. Pinecone serves fresh, filtered query results with low latency at the scale of billions of vectors.

Weaviate
Weaviate is an open-source vector database. It allows you to store data objects and vector embeddings from your favorite ML-models, and scale seamlessly into billions of data objects.

Chroma
Chroma is the open-source embedding database. Chroma makes it easy to build LLM apps by making knowledge, facts, and skills pluggable for LLMs.

LanceDB
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrevial, filtering and management of embeddings.

Milvus
Milvus is an open-source vector database built to power embedding similarity search and AI applications. Milvus makes unstructured data search more accessible, and provides a consistent user experience regardless of the deployment environment.

Qdrant
Qdrant is a vector similarity search engine and vector database. It provides a production-ready service with a convenient API to store, search, and manage points—vectors with an additional payload.

Supabase
Supabase is an open source Vector database for developing AI applications. Use pgvector to store, index, and access embeddings, and our AI toolkit to build AI applications with Hugging Face and OpenAI.
Vercel Postgres
Vercel Postgres is a serverless SQL database designed to integrate with Vercel Functions and your frontend framework. With pgvector for vector similarity search, you can build semantic search applications with Next.js and the Vercel AI SDK.
How to Use a Vector Database
Using a vector database is not very different from using any other kind of database, though the operations you'd perform might vary based on the specific nature of vector data. Here's a simple guide to get started:
- Installation & Setup: Begin by choosing the right vector database for your needs. Once chosen, follow the provided installation guide. Many databases offer cloud-based solutions, so setup can be as simple as creating an account.
- Data Ingestion: Import your vector data into the database. This step might require you to convert your data into a vector format if it isn't already.
- Querying: Once your data is in place, you can start querying the database to find similar vectors or perform analytical operations. Most vector databases will provide you with a query language or an API that's tailored to handle vector operations.
- Maintenance & Scaling: As with any database, you'd need to monitor performance, handle backups, and ensure that your database scales with your needs.
Building a semantic search app with Vercel Postgres and pgvector
In this guide, we will learn how to build a semantic search pokedex app using Vercel Postgres and pgvector as the vector database.
You can check out a live demo, or deploy your own version of the template with one click.
Step 1: Clone the repository and set up required environment variables
First, clone the repository and download it locally.
git clone https://github.com/vercel/examples/tree/main/storage/postgres-pgvectorNext, you'll need to set up environment variables in your repo's .env.local file. Copy the .env.example file to .env.local. You will then need to add the following environment variables: OpenAI API key, which you can find here, as well as your Postgres credentials.
OPENAI_API_KEY=POSTGRES_URL=POSTGRES_URL_NON_POOLING=POSTGRES_USER=POSTGRES_HOST=POSTGRES_PASSWORD=POSTGRES_DATABASE=For the purpose of this guide, we'll use a free Postgres database hosted on Vercel. First, go to your Vercel dashboard select the Storage tab. Then select the Create Database button, select Postgres and then the Continue button.
To create a new database, do the following in the dialog that opens:
- Enter
sample_postgres_db(or any other name you wish) under Store Name. The name can only contain alphanumeric letters, "_" and "-" and can't exceed 32 characters. - Select a region. We recommend choosing a region geographically close to your function region (defaults to US East) for reduced latency.
- Click Create.
Our empty database is now created in the region specified.
Going back to your terminal, run npm i -g vercel@latest to install the Vercel CLI. Then, pull down the latest environment variables to get your local project working with the Postgres database.
vercel env pull .envWe now have a fully functioning Vercel Postgres database and have all the environment variables to run it locally and on Vercel.
Step 2: Install required dependencies and seed the database
Finally, install the required packages using your preferred package manager (e.g. pnpm). Once that's done, build the app and run the development server:
pnpm ipnpm run buildBehind the scenes, the build command runs a seed script that automatically seeds your database with a list of Pokémons in the Pokédex, represented as vector embeddings.
for (const record of (pokemon as any).data) { const { embedding, ...p } = record
// Create the pokemon in the database const pokemon = await prisma.pokemon.create({ data: p, })
// Add the embedding await prisma.$executeRaw` UPDATE pokemon SET embedding = ${embedding}::vector WHERE id = ${pokemon.id} `
console.log(`Added ${pokemon.number} ${pokemon.name}`)}To save time, we are seeding the database with the pre-processed embeddings for each Pokémon. If you want to generate them yourself, you can use a generateEmbedding function to generate them on the fly:
async function generateEmbedding(_input: string) { const input = _input.replace(/\n/g, ' ') const embeddingData = await openai.embeddings.create({ model: 'text-embedding-ada-002', input, }) const [{ embedding }] = (embeddingData as any).data return embedding}
for (const record of (pokemon as any).data) { const embedding = await generateEmbedding(p.name);;
// Create the pokemon in the database const pokemon = await prisma.pokemon.create({ data: p, })
// Add the embedding await prisma.$executeRaw` UPDATE pokemon SET embedding = ${embedding}::vector WHERE id = ${pokemon.id} `
console.log(`Added ${pokemon.number} ${pokemon.name}`)
await new Promise((r) => setTimeout(r, 500)); // Wait 500ms between requests}Step 3: Run the app and deploy to Vercel
Once you've seeded the database with all the vector embeddings, you can now run your application.
pnpm run devOpen http://localhost:3000 with your browser to check out the running app. You can search for a given Pokémon based on their attributes or name:
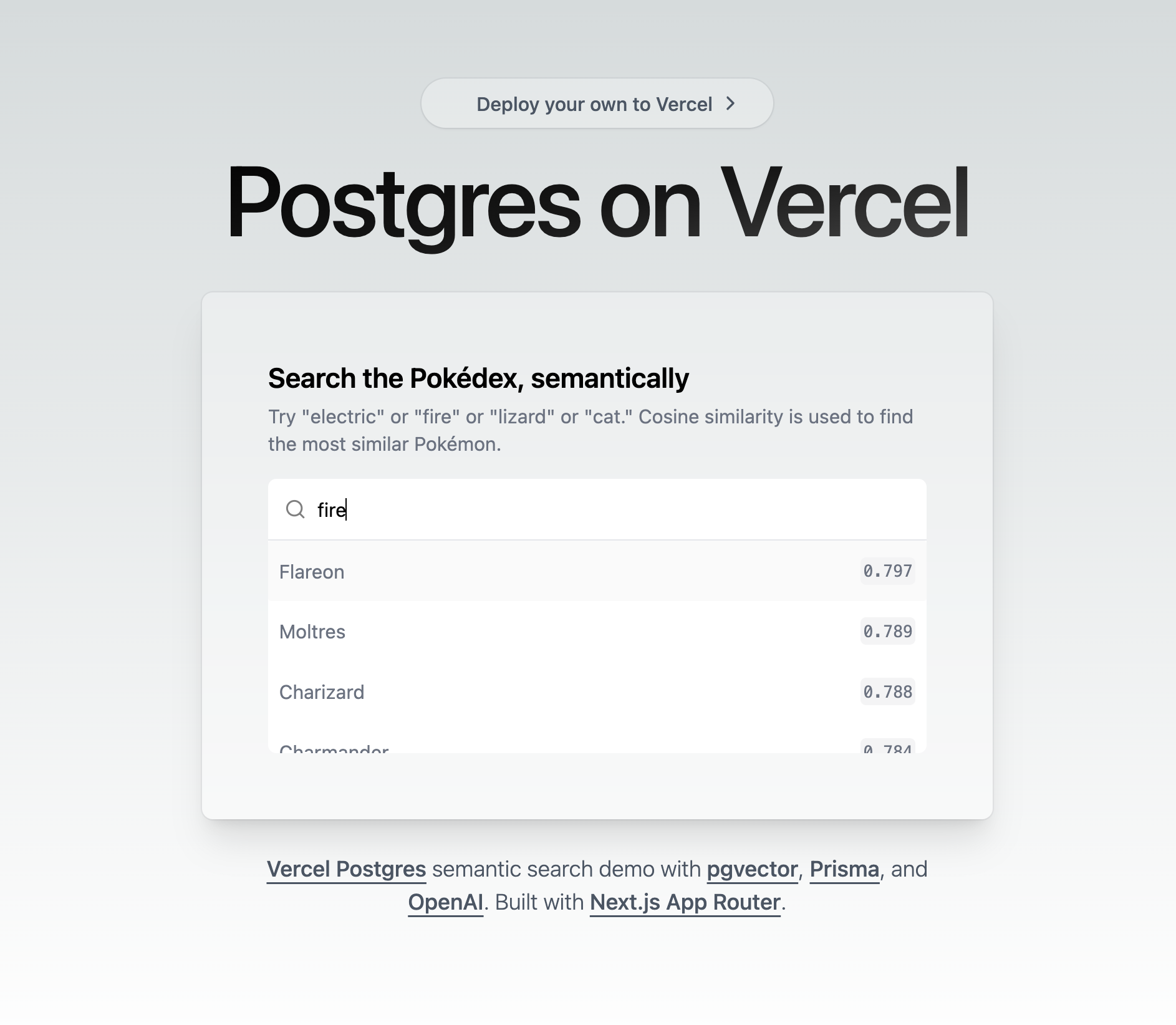
For the final step, you can deploy this application to Vercel – via Git or the Vercel CLI. Check out the docs on deploying an application to Vercel for more details.
Conclusion
Vector databases are incredibly powerful for extending the capabilities of large language models and building AI-enhanced product experiences. In this article, we learned about some of the best vector databases available in the market today, as well as how to leverage them to build a semantic search app using Vercel Postgres and pgvector.
